Riverpod's Flaws: A Critical Perspective


State management is a fascinating area in application development. The core idea is to provide a solid foundation for implementing business logic by being scalable, maintainable, and testable.
These things are interrelated, and it is all or nothing. So the solution can't be scalable and unmaintainable, or maintainable and untestable. There are many libraries that introduce their own approaches, using different patterns and specializing in specific paradigms.
In this article, I will take a closer look at a popular state management library called Riverpod. It was created by Rémi Rousselet, the cool Flutter engineer and author of many popular libraries including Provider and Freezed.
However, despite its popularity, Riverpod is a somewhat controversial solution, and the first thing that is questionable is its heavy reliance on global scope. We will examine everything and discuss the pros & cons.
Purposes of riverpod

In general, a package should solve a specific problem. For example, Bloc (by Felix Angelov) solves the problem of state management by applying the business logic component pattern. Sentry solves the problem of error monitoring. Firebase Analytics solves analytics problem.
Optimally, a package should address a singular issue effectively. Yet, in application development, it's frequent to encounter packages designed to tackle multiple issues. This approach typically leads to tightened coupling and complexity. These situations are often accompanied by dependency risks and a plethora of other challenges.
At the same time, Riverpod provides ways to implement business logic and acts as a "replacement for patterns like singletons, service locators, dependency injection, or inherited widgets". We'll talk about these "replacements" a bit later in this article, and for now let's focus on it as a state management solution.
Riverpod as a state management solution
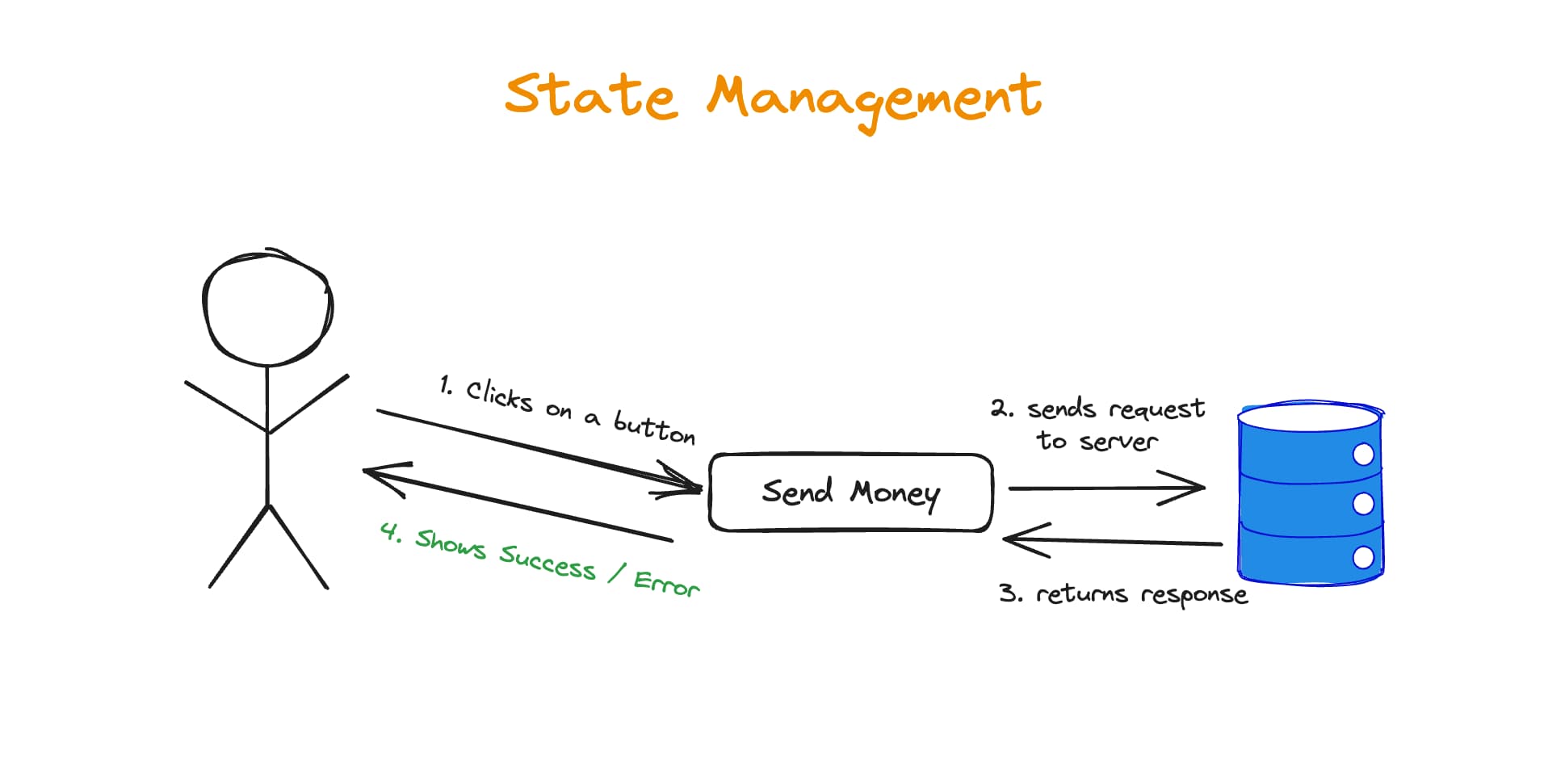
As I mentioned in the beginning, state management is a critical part of an application, as important as the user interface itself. Basically, the approach you choose defines your architectural options and limitations. It should be chosen very carefully.
If you choose a bad approach, the three pillars will be affected. If these pillars are affected -> your business is affected. Bugs show up and show up, adding new features becomes more and more difficult (fragility and rigidity). Usually, such problems are not foreseen and appear after a few months (or even weeks).
That brings us to Riverpod. As we agreed earlier, let's temporarily consider it as a tool for state management only. Riverpod has providers for this purpose. In fact, everything works here thanks to providers. According to documentation, you can think of providers as an access point to a shared state.
The code for a provider making a network request looks like this:
final activityProvider = FutureProvider.autoDispose((ref) async {
// Using package:http, we fetch a random activity from the Bored API.
final response = await http.get(Uri.https('boredapi.com', '/api/activity'));
// Using dart:convert, we then decode the JSON payload into a Map data structure.
final json = jsonDecode(response.body) as Map<String, dynamic>;
// Finally, we convert the Map into an Activity instance.
return Activity.fromJson(json);
});This code defines FutureProvider - a special type of Provider which is suited for async APIs. It performs get request, decodes and parses it into Activity.
Providers are lazy by default, and their values aren't evaluated until they're consumed. For example, to execute this request, you must first consume the value of this provider in a widget or other provider. Then riverpod will automatically cache it so that another read will use the cached value.
There are other types of providers:
- Default provider. Used to compute something synchronously (for example, return an instance of a class)
- StreamProvider. Useful for working with stream APIs
- NotifierProviders. Providers that use a notifier internally
Let's create a small application using this future provider (it will just fetch the data from the API, parse it, and display it on a screen). First, the root of all widgets should be wrapped in ProviderScope as follows:
void main() {
runApp(
const ProviderScope(child: MainApp()),
);
}
ProviderScope is an inherited widget that provides access to the ProviderContainer. This is where provider values are stored and cached.
Okay, let's create a model:
@freezed
class Activity with _$Activity {
factory Activity({
required String key,
required String activity,
required String type,
required int participants,
required double price,
}) = _Activity;
/// Convert a JSON object into an [Activity] instance.
/// This enables type-safe reading of the API response.
factory Activity.fromJson(Map<String, dynamic> json) =>
_$ActivityFromJson(json);
}And the widget will look as follows:
class Home extends StatelessWidget {
const Home({super.key});
@override
Widget build(BuildContext context) {
return Scaffold(
body: Consumer(
builder: (context, ref, child) {
final AsyncValue<Activity> activity = ref.watch(activityProvider);
return Center(
/// Since network-requests are asynchronous and can fail, we need to
/// handle both error and loading states. We can use pattern matching for this.
/// We could alternatively use `if (activity.isLoading) { ... } else if (...)`
child: switch (activity) {
AsyncData(:final value) => Text('Activity: ${value.activity}'),
AsyncError() => const Text('Oops, something unexpected happened'),
_ => const CircularProgressIndicator(),
},
);
},
),
);
}
}In the widget above, I've used a consumer widget. This is the widget provided by flutter_riverpod. It gives access to the Ref which itself is a reference to ProviderContainer obtained via InheritedWidget called ProviderScope.
So this code watches the global variable called activityProvider. In case of success, we display "Activity: {response}". On error, we render "Oops, something unexpected happened". Otherwise, we return the circular progress indicator.
Everything looks easy! But why am I worried? Let's analyze what's happenning here.
Concern #1 - Global Scope
While the documentation says "Do not feel threatened by the fact that a provider is declared as a global. While providers are globals, the variable is completely immutable. This makes creating a provider no different than declaring a function or class", I still feel threatened.
Yes, providers are immutable and don't contain state. But they serve as a link to a place where that state is stored. Imagine having a map where keys are providers and values are their cache. The same is true for Riverpod, though more difficult.
Although authors say that the fact that providers are usually global doesn't matter, I want to prove to you why it's a little different. To visualize:
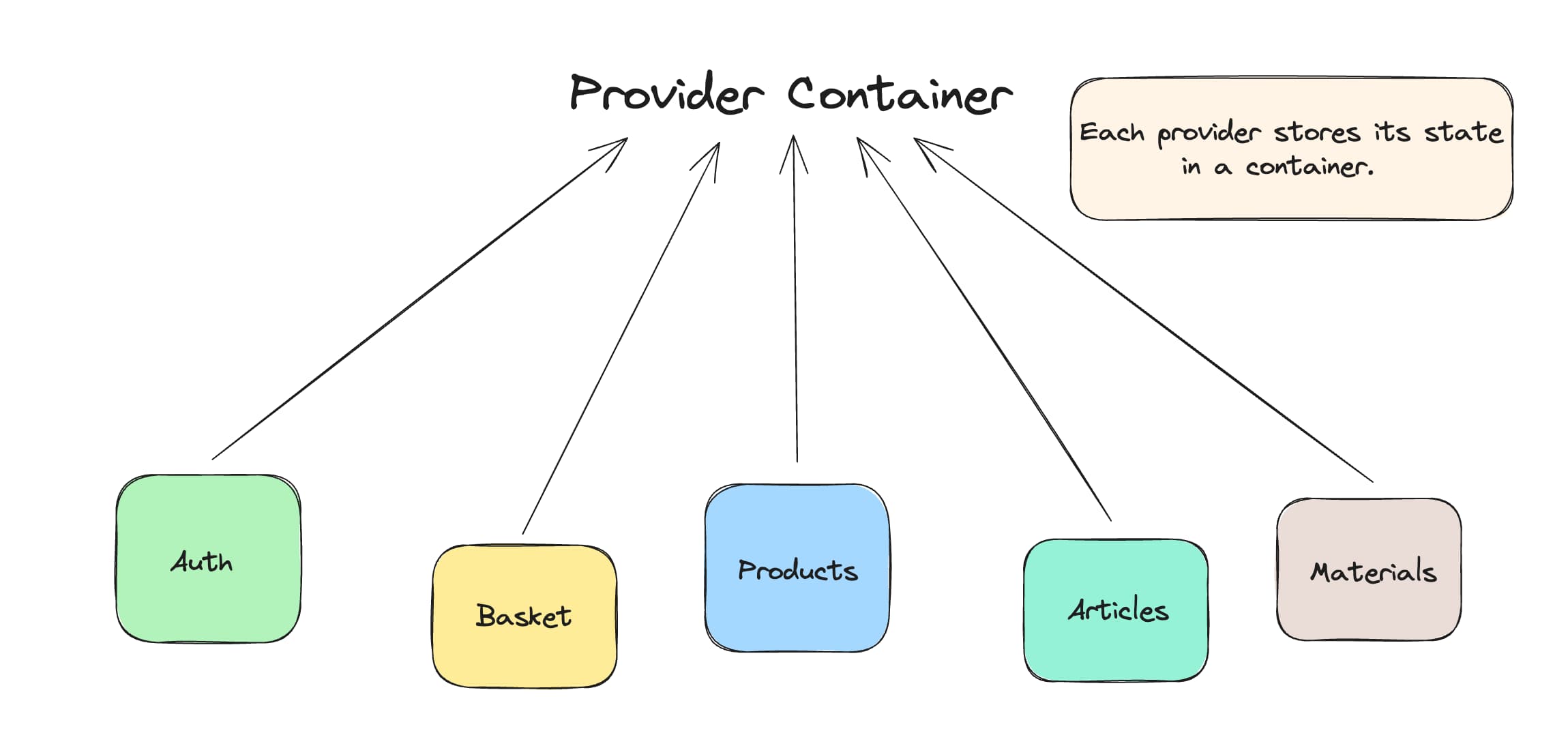
Each provider stores its state in the root, regardless of whether that provider is used in the root or somewhere very deep in the application. The ability to access providers from anywhere has its consequences.
Although you can't change the value of a provider, you can ask it to recompute its value from anywhere. It's also quite common to use non-disposing providers, i.e. ones that don't dispose when you close the screen.
This encourages less disciplined coding practices. Since you can read providers from anywhere, you may end up having direct dependencies on other providers and consuming providers that are not appropriate for that particular location.
Concern #2 - Coupling
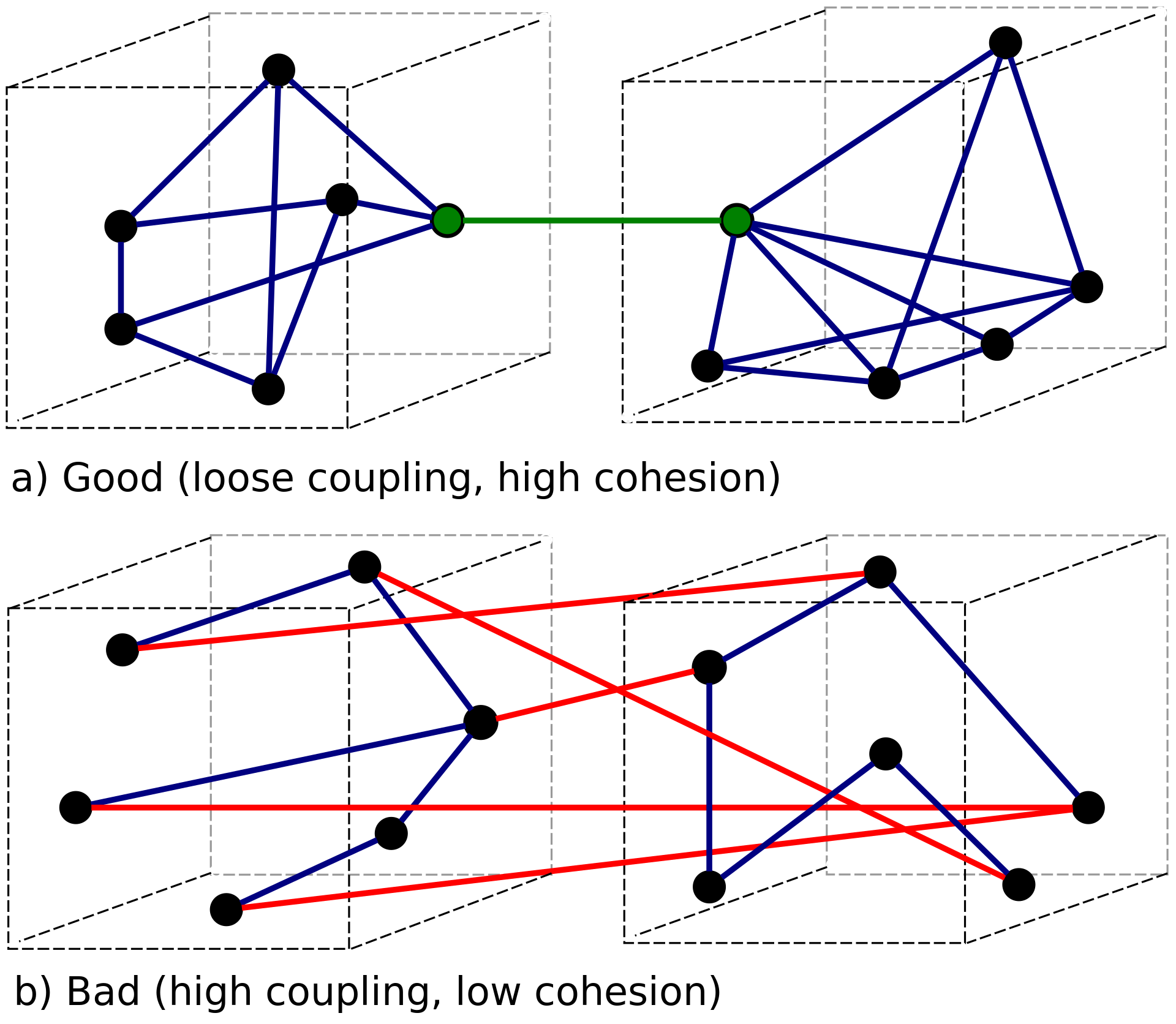
Coupling describes the level of dependency between various parts of a software. Ideally, one aims for low (loose) coupling, enhancing the ease of modifying, comprehending, and reusing individual components without impacting other segments of the software.
Conversely, high (tight) coupling can lead to complications and increase the likelihood of errors during modifications, as the interconnected components require simultaneous understanding and alterations.
Consider an example with two Riverpod providers: Users and Products. Here, the Products provider relies on specific user data to load its products. In such scenarios, Riverpod documentation typically advises directly observing the Users provider from within the Products provider:
final userProvider = FutureProvider<String>((ref) async {
return Future.delayed(const Duration(seconds: 1), () => "Mark");
});
final productsProvider = FutureProvider<List<String>>((ref) async {
final user = await ref.watch(userProvider.future);
return Future.delayed(
const Duration(seconds: 1),
() => List.generate(5, (index) => "$user's product ${index + 1}")
);
});Currently, the product provider is monitoring the user provider through its 'ref'. If there's any update to the user, for example, a change in the user's name, the value within the productsProvider is recomputed automatically. This might seem advantageous at first glance. However, the critical issue with this method is its inherent coupling.
The coupling of the product provider with the user provider creates a direct dependency, leading to several issues. When the user provider alters its logic, return type, model, or conditions, it necessitates changes in the product provider. This includes managing the response and determining whether to return a new state or an error. Such tight integration limits the reusability of the productsProvider, especially in contexts where the user is obtained differently, necessitating decoupling for flexibility.
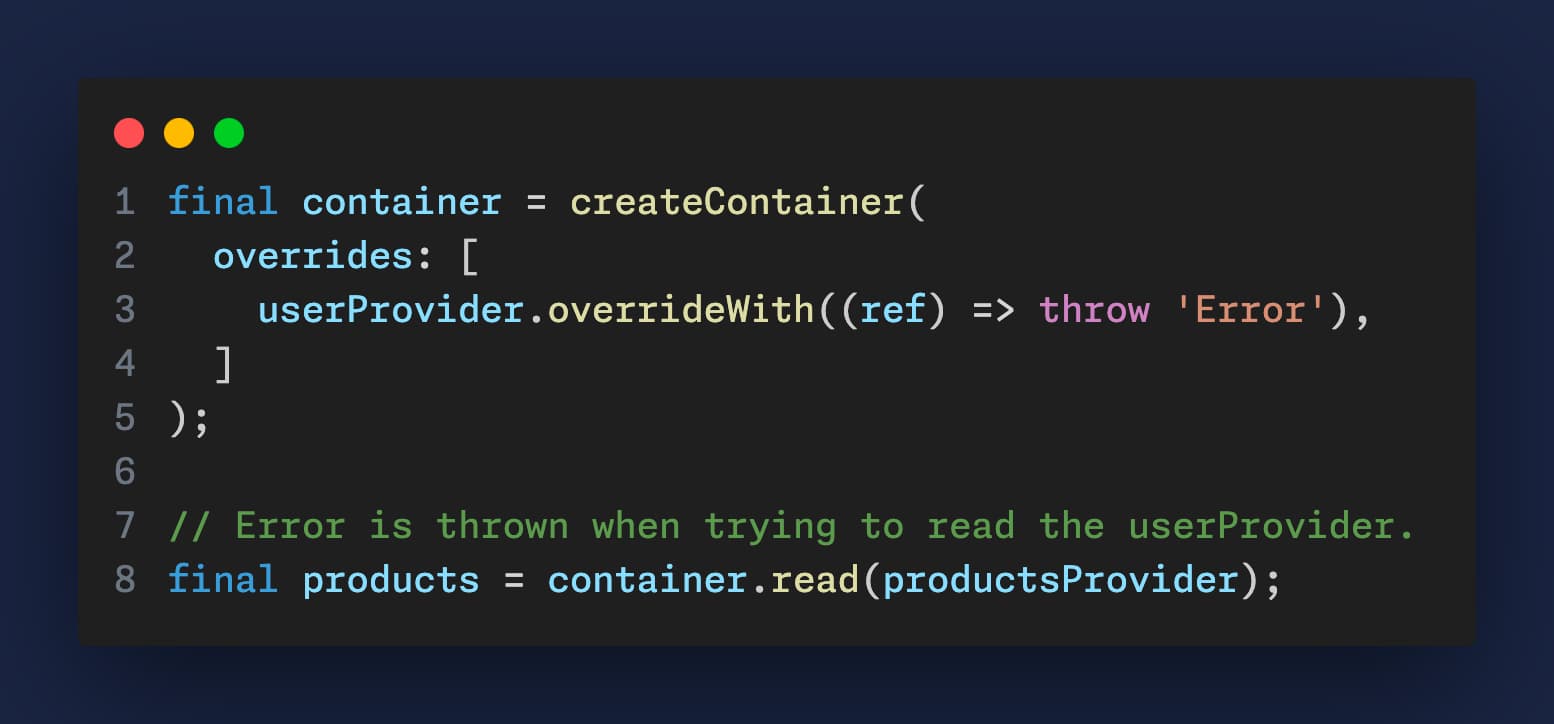
Testing is another challenge, as it becomes more difficult to conduct in isolation due to the constant need to set up the userProvider. The scalability of the application is also affected. As the application grows and more providers are intertwined, the system's complexity increases significantly, complicating the addition of new features or modification of existing ones due to the intricate web of interdependencies.
Additionally, these dependencies can cause unintended side effects, like unnecessary notifications or re-renders. Furthermore, when a provider extends beyond managing its state to handling the logic of other providers, it violates the Single Responsibility Principle (SRP), further complicating the architecture.
How to reduce coupling

To improve the maintainability, scalability, and testability of your components, it's critical to minimize their interdependencies. But what's the best way to do that?
You may find parallels with bloc architecture, particularly in the area of inter-bloc communication. This concept, which is detailed in a special section of the bloc documentation here, offers insights into how to respond to state changes in other blocs. It's worth a read if you haven't already, and it complements the principles discussed in this article.
To reduce coupling in your design, consider avoiding direct dependencies by not using ref in the provider. Instead, use the Family Builder to transfer necessary information or dependencies from another provider. Creating provider wrappers for scoping is another viable strategy.
An important guideline is to avoid embedding business logic directly in providers. This is better handled by building separate modules. In addition, implementing notifiers and accessing data via reactive repositories can be an effective approach.
Concern #3 - Testing

Let's delve into the topic of testing. Testing is an essential process that ensures our software meets specific standards and requirements. While it's not a cure-all, its usefulness in software development is significant.
The main issue here is the problem of coupling. When one provider relies on another, isolating them for individual testing becomes challenging. This leads to a situation where, instead of testing a single provider, we end up evaluating an entire network of interconnected providers.
This is where the ability to mock providers becomes crucial, and riverpod offers this capability. However, relying on this feature can sometimes act more as a temporary fix rather than a comprehensive solution. Consider the following code:
import 'package:riverpod/riverpod.dart';
import 'package:test/test.dart';
/// A testing utility which creates a [ProviderContainer] and automatically
/// disposes it at the end of the test.
ProviderContainer createContainer({
ProviderContainer? parent,
List<Override> overrides = const [],
List<ProviderObserver>? observers,
}) {
// Create a ProviderContainer, and optionally allow specifying parameters.
final container = ProviderContainer(
parent: parent,
overrides: overrides,
observers: observers,
);
// When the test ends, dispose the container.
addTearDown(container.dispose);
return container;
}
// An eagerly initialized provider.
final exampleProvider = FutureProvider<String>((ref) async => 'Hello world');
// In unit tests, by reusing our previous "createContainer" utility.
final container = createContainer(
// We can specify a list of providers to mock:
overrides: [
// In this case, we are mocking "exampleProvider".
exampleProvider.overrideWith((ref) {
// This function is the typical initialization function of a provider.
// This is where you normally call "ref.watch" and return the initial state.
// Let's replace the default "Hello world" with a custom value.
// Then, interacting with `exampleProvider` will return this value.
return 'Hello from tests';
}),
],
);
// We can also do the same thing in widget tests using ProviderScope:
await tester.pumpWidget(
ProviderScope(
// ProviderScopes have the exact same "overrides" parameter
overrides: [
// Same as before
exampleProvider.overrideWith((ref) => 'Hello from tests'),
],
child: const YourWidgetYouWantToTest(),
),
);This code defines a createContainer function which creates that storage. Ideally, you should create this for each test. Let's do some testing. Consider this code for products and users:
class ProductsRepository {
Future<List<String>> getProducts(String user) async {
await Future.delayed(const Duration(milliseconds: 200));
return ['Product 1', 'Product 2', 'Product 3'];
}
}
class UserRepository {
Future<String> getUser() async {
await Future.delayed(const Duration(milliseconds: 200));
return 'User';
}
}
final userRepository = Provider((ref) => UserRepository());
final productsRepository = Provider((ref) => ProductsRepository());
final userProvider =
FutureProvider((ref) => ref.watch(userRepository).getUser());
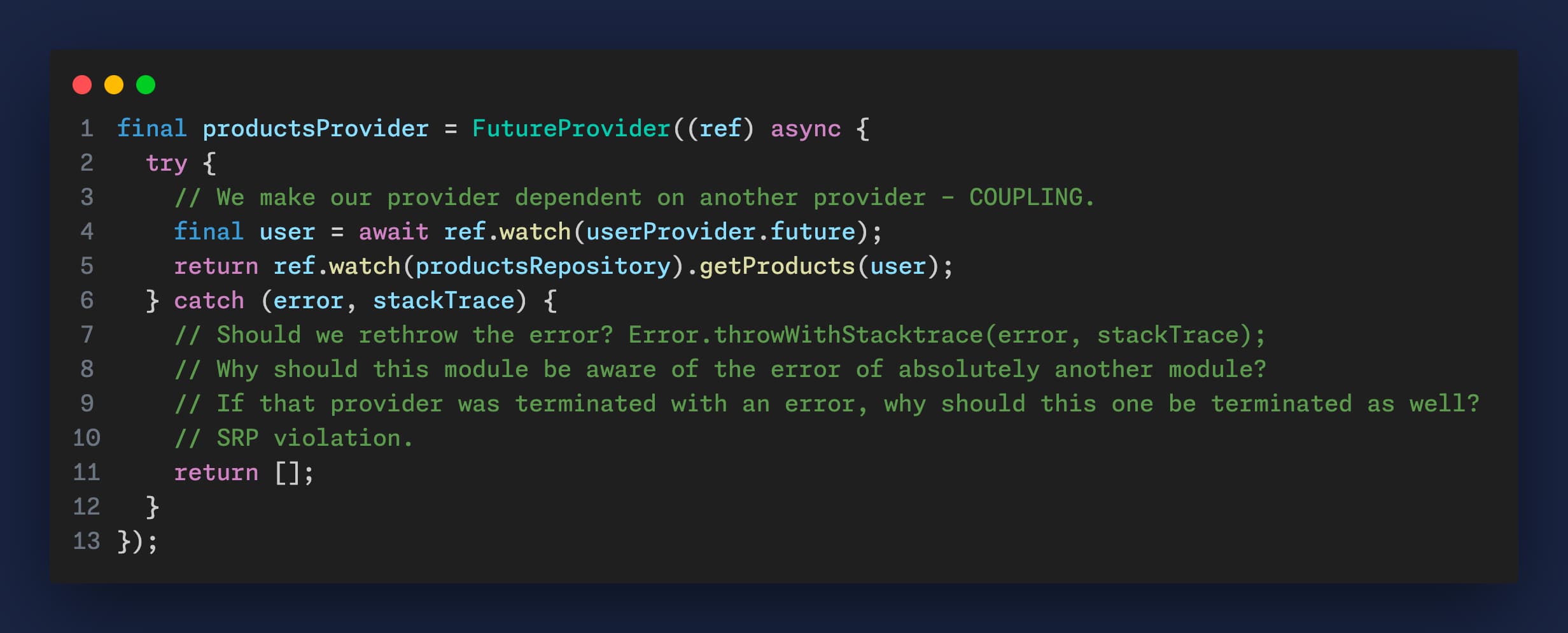
final productsProvider = FutureProvider((ref) async {
try {
// We make our provider dependent on another provider - COUPLING.
final user = await ref.watch(userProvider.future);
return ref.watch(productsRepository).getProducts(user);
} catch (error, stackTrace) {
// Should we rethrow the error? Error.throwWithStacktrace(error, stackTrace);
// Why should this module be aware of the error of absolutely another module?
// If that provider was terminated with an error, why should this one be terminated as well?
// SRP violation.
return [];
}
});Typical test will look like this:
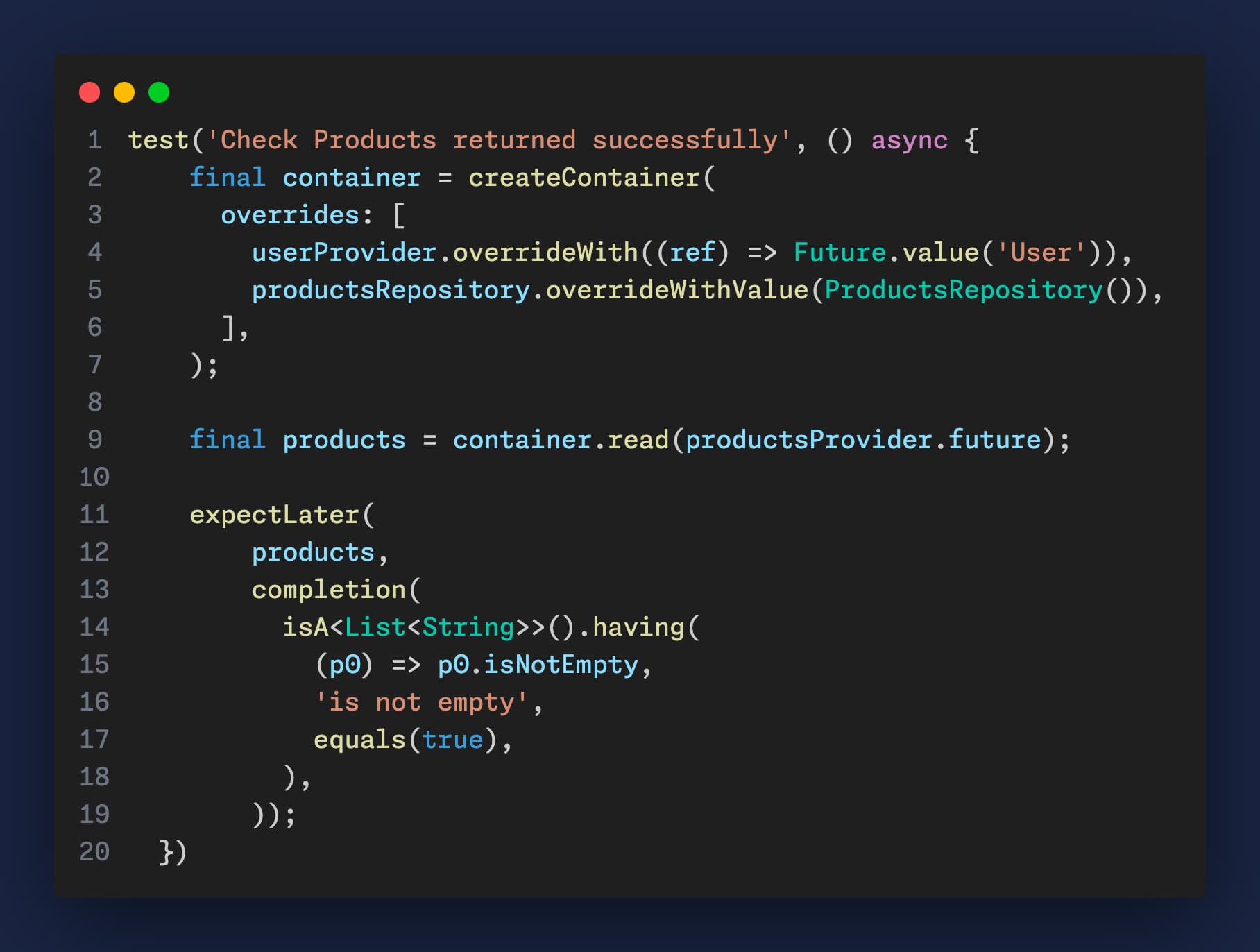
Setting up the container with the right overrides for each test can be error-prone. Misconfiguration can lead to tests that pass incorrectly (false positives) or fail for reasons unrelated to the test's intent.
The test is tightly coupled to the service locator pattern. This coupling can make it harder to refactor the code or change the dependency management approach later on.
The actual dependencies of productsProvider are not immediately clear from the test itself. This lack of transparency can make understanding and maintaining tests more difficult, as you have to know which services to override for each test scenario.
Concern #4 - Imperative Paradigm & Side Effects

The term "imperative API" refers to a style of programming where you explicitly tell the program what to do and how to do it, as opposed to a "declarative API" where you describe what you want and the system figures out how to achieve it.
Riverpod claims to be declarative. Let us look at the invalidate API. The concept of "invalidating" a provider involves directly and explicitly telling the provider to refresh or reload its state.
This is in contrast to a more declarative approach, where the state might be updated automatically based on certain conditions or dependencies, without the need for a direct command from the developer.
When you invalidate a provider, you are explicitly telling the system to discard the current state and possibly fetch or compute a new state. This is direct state manipulation, which is a hallmark of imperative programming.
Invalidation often requires manual intervention by the developer. You decide when and where to invalidate the provider, as opposed to setting up rules or conditions under which the provider would automatically update itself.
The act of invalidating a provider typically follows a procedural step in the code, where you first perform some actions (such as updating a database or changing a variable), and then explicitly call the invalidate method. This sequence of steps is characteristic of imperative programming.
Look at this code from the documentation:
class TodoList extends AutoDisposeAsyncNotifier<List<Todo>> {
// Loads the list of todos.
@override
Future<List<Todo>> build() async => [/* ... */];
// Adds a new todo to the list.
Future<void> addTodo(Todo todo) async {
// We don't care about the API response
await http.post(
Uri.https('your_api.com', '/todos'),
headers: {'Content-Type': 'application/json'},
body: jsonEncode(todo.toJson()),
);
// Once the post request is done, we can mark the local cache as dirty.
// This will cause "build" on our notifier to asynchronously be called again,
// and will notify listeners when doing so.
// IMPERATIVE + SIDE EFFECTS!
ref.invalidateSelf();
// (Optional) We can then wait for the new state to be computed.
// This ensures "addTodo" does not complete until the new state is available.
await future;
}
}The code example provided illustrates a direct HTTP request initiated from the business logic component, specifically the state notifier. This approach violates the principle of separation of concerns. Such a practice, especially when presented to novices, can lead to a common pitfall where data handling and business logic are inappropriately intertwined. It's important to address this, even if it's not the primary focus here.
In the current structure, the code lacks adherence to a declarative style, leaning instead toward an imperative approach. This method is fraught with potential errors and lacks robustness, resulting in a convoluted process for updating the state. The execution flow becomes complex and prone to unintended side effects.
For example, adding a todo item triggers an HTTP request and simultaneously invalidates the provider. This action inadvertently calls the build method, which then recomputes the state. The control flow then unexpectedly returns to the addTodo function, where additional business logic is executed. This pattern creates a convoluted and inefficient process that needs to be streamlined for greater clarity and reliability.
Concern #5 - Separation of Concerns

Understanding the architecture of software development is crucial, and a key principle in this regard is the 'separation of concerns'. This principle advocates for dividing the architecture into well-defined layers, each with specific responsibilities and strict interaction rules.
Typically, I organize architecture into three layers: the widget, business logic, and data layers. The widget layer focuses on describing UI, the business logic layer serves as an intermediary and defines business rules, and the data layer encompasses repositories and data sources, handling data retrieval and manipulation.
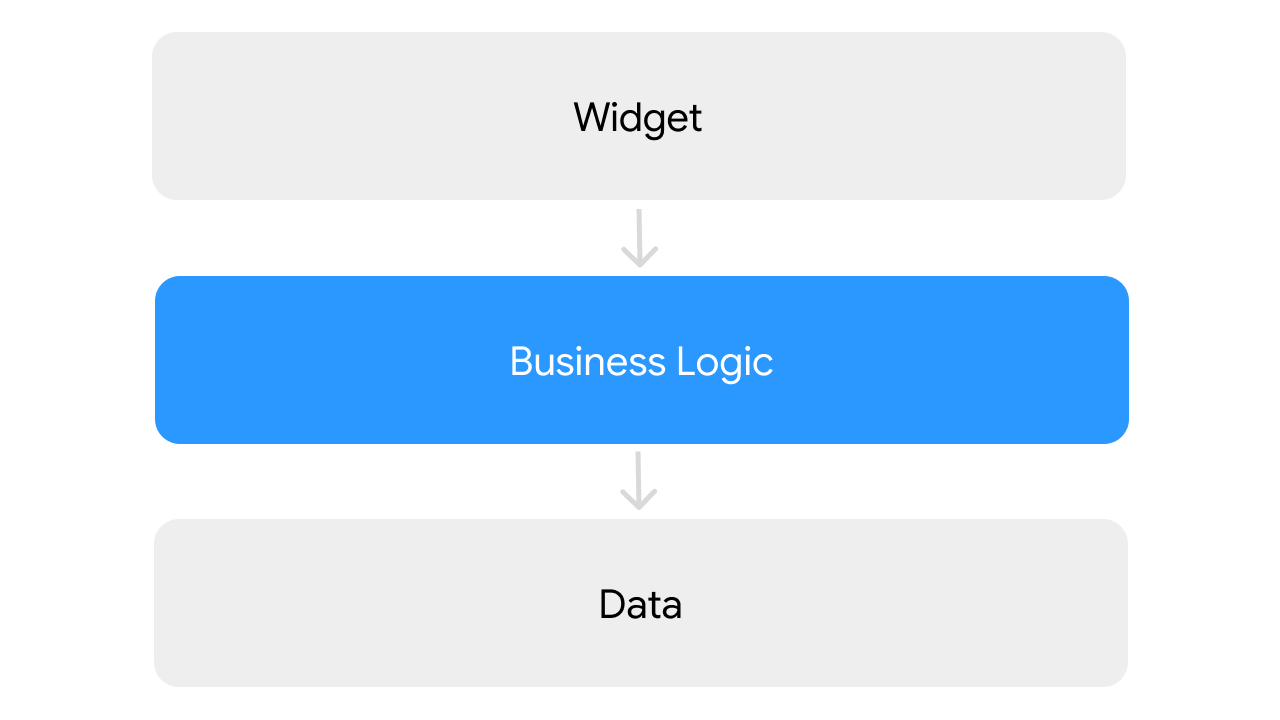
The concept of separation of concerns in Riverpod seems a bit vague. An example from a previous point demonstrates the execution of an HTTP request within a provider, and a similar pattern is observed with websockets.
Riverpod's general approach, evident in FutureProviders / StreamProviders and its broader documentation, leans toward integrating data directly into providers rather than maintaining it in separate entities. This integration can reduce the flexibility of the providers and create a stronger dependency on Riverpod, as the business logic is also embedded in these providers. This mix of functionality in a single place can be problematic.
Providers in Riverpod are intended to handle dependency management and serve as an alternative to traditional dependency injection techniques. However, they often lead to the formation of unseen subscriptions and dependencies, similar to other service locators.
In addition, providers are tasked with monitoring and managing their cache, which involves establishing caching policies. To illustrate, here's an example from the Riverpod documentation:
final myProvider = FutureProvider.autoDispose((ref) async {
final response = await httpClient.get(...);
ref.keepAlive();
return response;
});
This code snippet shows a provider managing its cache and lifecycle. However, this raises a question: should a module be aware of and control how its data is stored and managed within the system? The responsibility for deciding whether to keep a module alive or discard it should rest with widgets.
As the ultimate consumers of these modules, widgets are in a better position to understand and manage their interactions with modules. This perspective is more in line with modular design principles and improves the separation of concerns within the application architecture.
Concern #6 - Magic

In programming, the term "magic" often refers to the intricate, behind-the-scenes processes that drive an application, although these are not inexplicable phenomena. In Flutter, for example, the complex mechanisms of compositing, painting phases, render objects and elements are more methodical and well-defined than "magic".
What I'm referring to as "magic," however, are the additional, less transparent activities that affect the flow of applications and data, and that occur autonomously, often without the direct intervention or awareness of the developer. A pertinent example from Riverpod is its caching and disposal logic, in addition to its interaction with consuming providers.
In this context, Riverpod generates side effects that can introduce elements of unpredictability or opacity into the flow of the application. These side effects are not always immediately apparent to developers and can create challenges in understanding and managing the behavior of the application.
While this "magic" aspect is beneficial in reducing boilerplate code and enhancing functionality, it also adds a layer of complexity in understanding how changes in one part of the system may affect others.
Also, flutter_hooks and riverpod_hooks contribute to this aspect even more, add additional complexity and solve non-existent problems.
Providers vs Dependency Injection
Riverpod documentation proposes providers as a complete replacement for traditional patterns such as Singletons, Service Locators, Dependency Injection, or InheritedWidgets. This raises an important question: Can Riverpod effectively compete with Dependency Injection as a replacement?
Dependency Injection is a well-known method for managing module dependencies with the critical purpose of expounding and clarifying module dependencies. This is typically achieved by constructing a constructor that encompasses all necessary dependencies.
The clarity of dependencies significantly enhances the predictability and maintainability of modules, as it allows for an explicit listing of required dependencies. This transparency is particularly beneficial for testing purposes. Furthermore, Dependency Injection reduces coupling between components.
Since components do not create their own dependencies, substituting them with alternate implementations becomes easier. Therefore, components designed with Dependency Injection tend to be more reusable, without any hard-coded dependencies.
By separating the creation of dependencies from the behavior of a class, Dependency Injection typically leads to code that is cleaner and easier to understand. It promotes a coding style consistent with the SOLID principles of object-oriented design, leading to more resilient, manageable, and cohesive applications.
In contrast, Riverpod's approach deviates from these advantages. Its methodology suggests a system with more tightly coupled modules, potentially complicating debugging and testing processes. With this framework, modules tend to be less reusable and maintainable.
Riverpod blends business logic with dependency resolution, a blend that can lead to less clarity in module dependencies compared to traditional DI methods. This integration affects the long-term scalability and adaptability of applications developed using Riverpod.
Final thoughts

In summary, this article highlights several key concerns with Riverpod:
- It obscures and tightens dependencies, reducing testability and reusability.
- By combining data and business logic within providers, it breaches the principle of separation of concerns.
- The framework necessitates the creation of global variables.
- It introduces side-effects, leading to a less transparent flow.
- Riverpod's providers lack scoping capabilities, making them unsuitable substitutes for Inherited Widgets or Dependency Injection systems.
I think senior engineers/architects will be able to overcome many of its problems, but will they use Riverpod? Probably, only as an argument :)
I would like to mention here my personal starter for Flutter with some architectural and organisational ideas - Sizzle Starter.
Thanks for reading
This article is coming to an end. Hats off to those of you who have read it all. Consider subscribing to my blog and telegram channel.
Perhaps you would like to debate, ask a question or say some kind words? Feel free to join the discussion below, I will be notified of any updates here, so go ahead!



